
Deepseek R1+Ollama+AnythingLLM搭建本地RAG知识库
注:以下为Windows10系统操作记录,16G内存,NVIDA 4060 8G显卡
什么是RAG
RAG(Retrieval-Augmented Generation)检索增强生成,是一种结合信息检索与生成式语言模型的混合架构,旨在提升生成式任务的事实性、准确性和可解释性。其核心思想是通过动态检索外部知识库中的相关文档片段,为生成模型提供上下文约束,从而缓解传统生成模型的“幻觉”问题,并支持对私有或动态更新的知识源的访问。
RAG核心流程
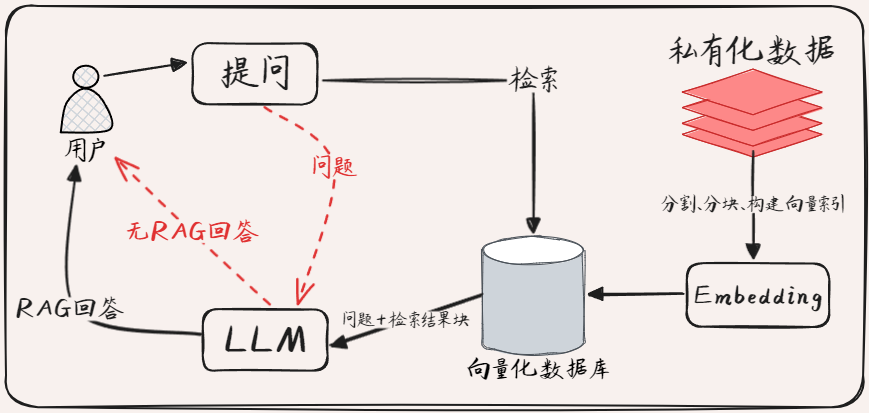
- 索引(Indexing)
- 文档分割:把文档库中的长文档拆分成较短的块(Chunk),每个 Chunk 应包含完整的语义信息,比如一个段落、一个句子等。这样做的目的是为了更精准地匹配用户的问题。
- 向量索引构建:利用编码器(比如Embedding向量化模型)将每个 Chunk 转换为向量表示,然后将这些向量存储到向量数据库中,构建向量索引,以便后续快速检索。
- 检索(Retrieval)
- 相似度计算:将用户提出的问题也转换为向量,然后在向量数据库中计算问题向量与各个 Chunk 向量之间的相似度。
- 文档片段筛选:根据相似度排序,选取相似度较高的 Chunk 作为相关文档片段。
- 生成(Generation)
- 上下文整合:将检索到的相关文档片段作为上下文信息。
- 答案生成:把问题和上下文信息输入到大语言模型LLM中,让模型根据上下文生成问题的回答
本文工具和模型
- Ollama—-开源软件,本地部署大模型
- Deepseek R1—- 开源LLM模型
- Nomic-Embed-Text—-开源嵌入向量模型
- AnythingLLM—-开源,LLM应用框架
Ollama相关
Ollama 是一个用于本地运行大型语言模型的开源软件
安装ollama
官网Ollama点击download进入下载页面选择Windows系统下载安装即可。
ollama安装问题记录
遇到一个问题,安装程序不能选择安装路径,会默认安装在C盘,Ollama本身占用约5G的空间,下载模型的目录默认也在C盘,会占用很多C盘空间。
如何安装到其他盘,豆包回复如下
- Windows 系统
- 使用命令行安装:找到 Ollama 的安装文件,一般是
.exe后缀的文件,在命令提示符(CMD)中进入该文件所在目录,然后使用命令.\\ollama setup.exe /dir=D:\\your desired location,将D:\\your desired location替换为你想要安装到的具体路径,如E:\\Ollama等,即可将 Ollama 安装到指定盘。 - 修改环境变量:安装时先让 Ollama 默认安装在 C 盘,安装完成后,打开系统环境变量设置,新增一个变量名为
OLLAMA_MODELS,变量值设置为你希望的安装路径,如D:\\Ollama。之后重新启动 Ollama 相关进程或命令行工具,这样 Ollama 下载的模型就会存储到指定路径,而不是 C 盘。
- 使用命令行安装:找到 Ollama 的安装文件,一般是
实际操作记录
-
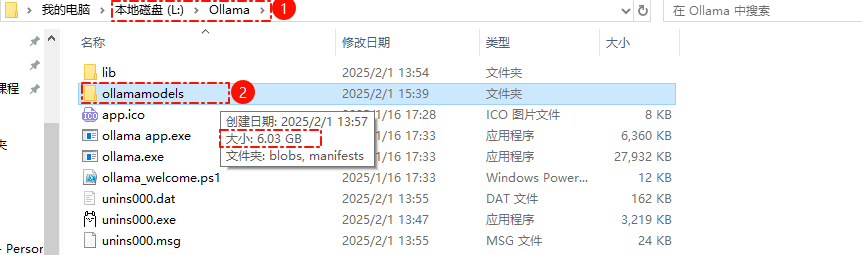
将ollama程序安装到L盘
.\OllamaSetup.exe /dir=L:/Ollama安装成功后任务栏会出现程序图标(右键单击图标可退出程序),打开cmd或其他终端命令行输入ollama --version检查
-
修改环境变量增加系统变量指定存储模型的路径,变量名
OLLAMA_MODELS变量值L:\Ollama\ollamamodels注意修改环境变量后,需要重启ollama程序生效
检查,结果符合预期(结合模型下载步骤)
模型下载
本地搭建私有知识库,主要需要两种模型,一类是LLM大语言模型,一类是Embedding向量模型
Ollama 命令如下, 其中run 、pull、 list比较常用
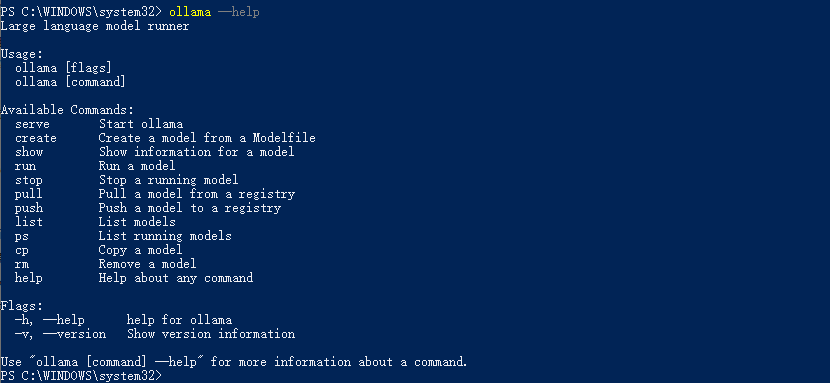
举例安装一个deepseek-r1:8b模型,一定要有success才是成功,上面那个bge-m3的模型,就是有问题失败了
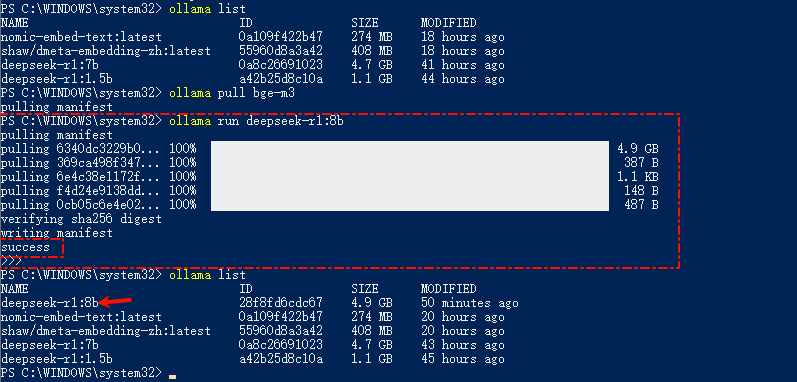
LLM模型下载
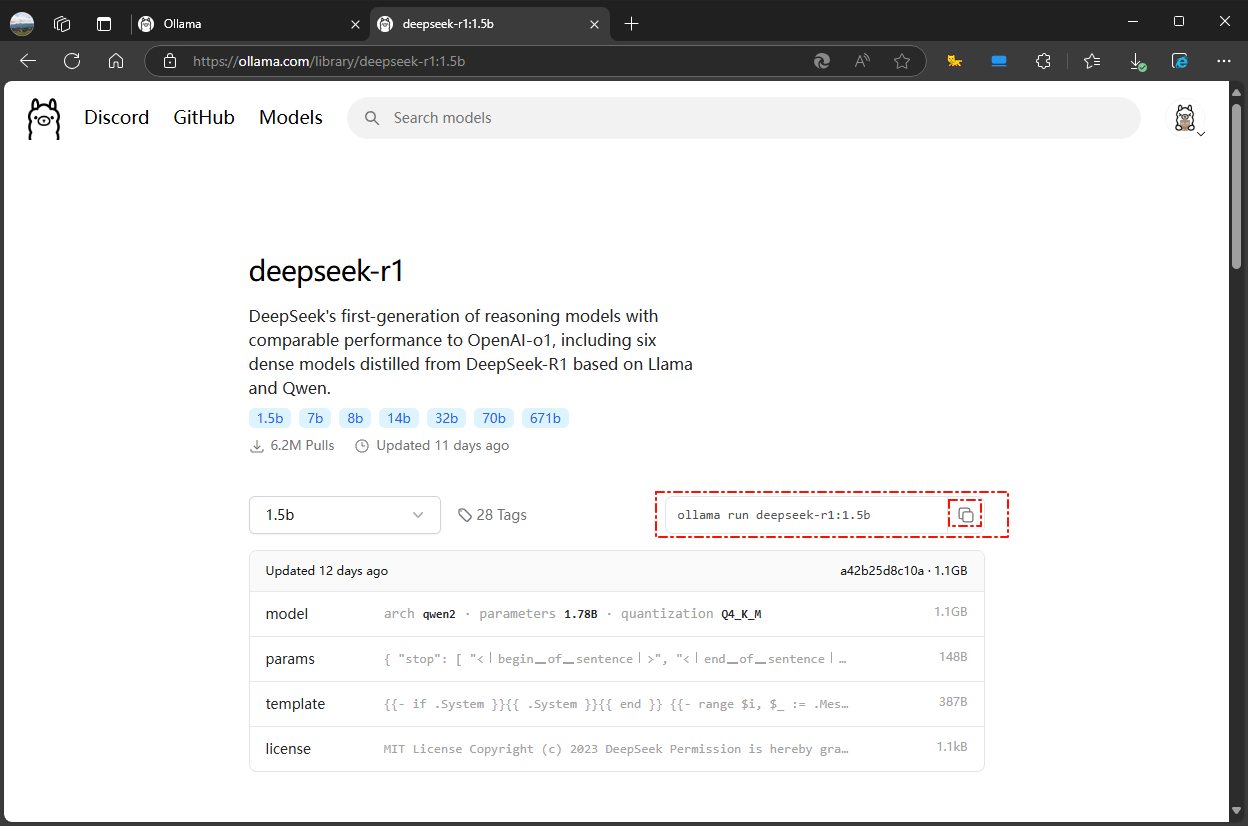
点击官网上的models进入选择Deepseek R1进行下载,1.5b的硬件要求最低,本机8G显存理论可跑7b 8b的;具体参考别人的评测
例如deepseek-r1:1.5b模型,点击复制命令ollama run deepseek-r1:1.5b`在终端命令窗口运行,run命令没有模型会自动安装,pull安装也可以。
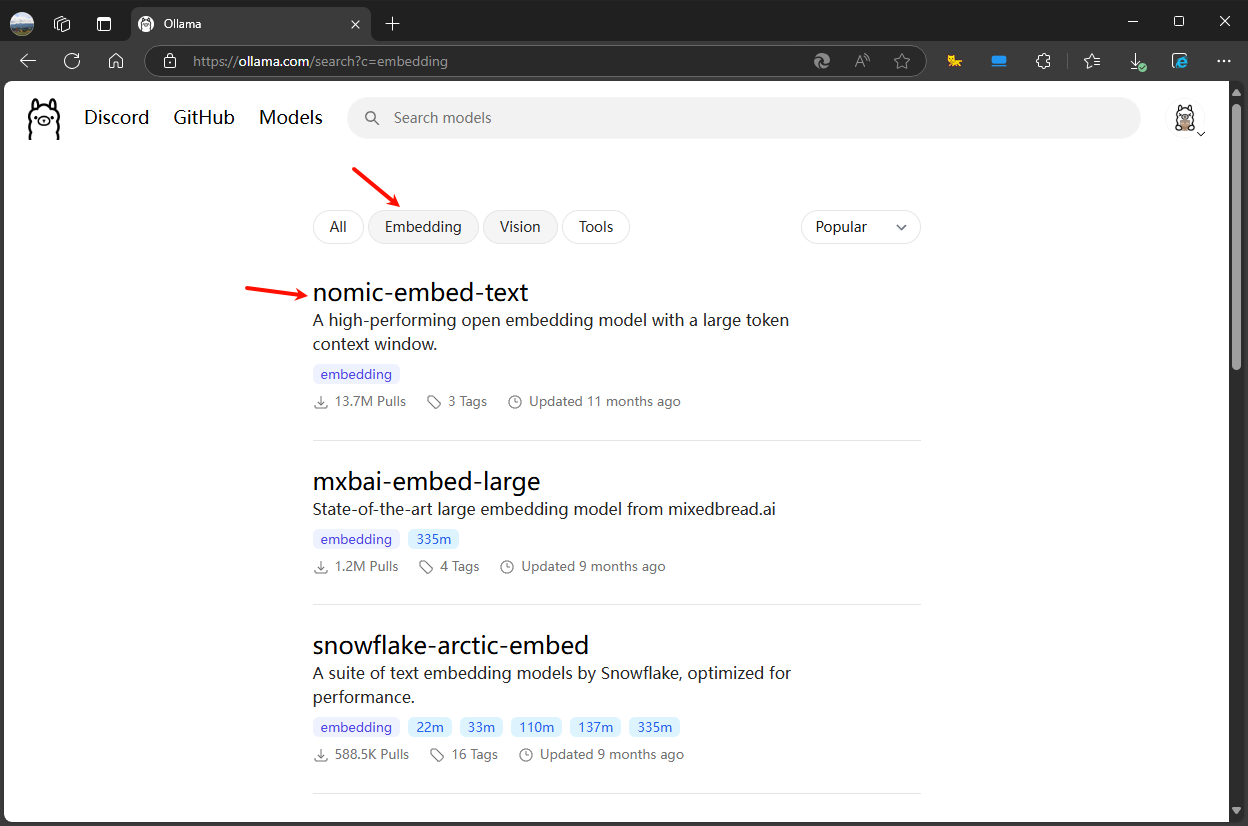
Embedding模型
下载步骤也一样,复制命令粘贴执行,选择一个文本处理能力强的体积小的nomic-embed-text模型测试
比如nomic-embed-text模型,复制ollama pull nomic-embed-text
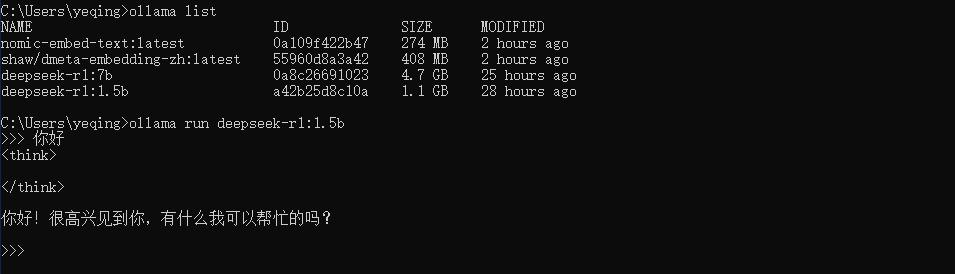
检查Ollama环境
ollama list查看已下载安装的模型ollama run deepseek-r1:1.5b运行此模型,<think> </think>标签下是R1推理的过程
GPU的情况
未运行大模型时GPU情况为1.3/8GB
ollama run deepseek-r1:1.5b运行时,2.9/8GB GPU占用约1.6GB
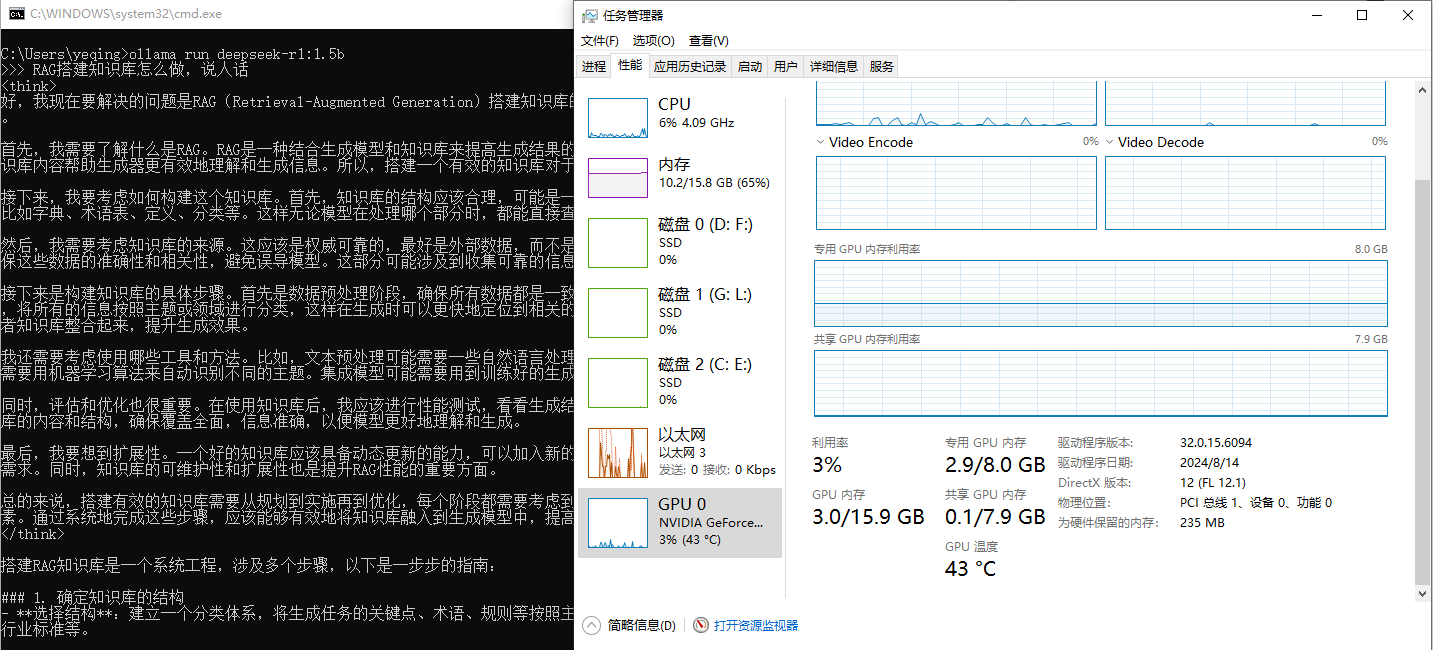
ollama run deepseek-r1:7b运行时,6.1/8.0GB,GPU占用约4.8GB
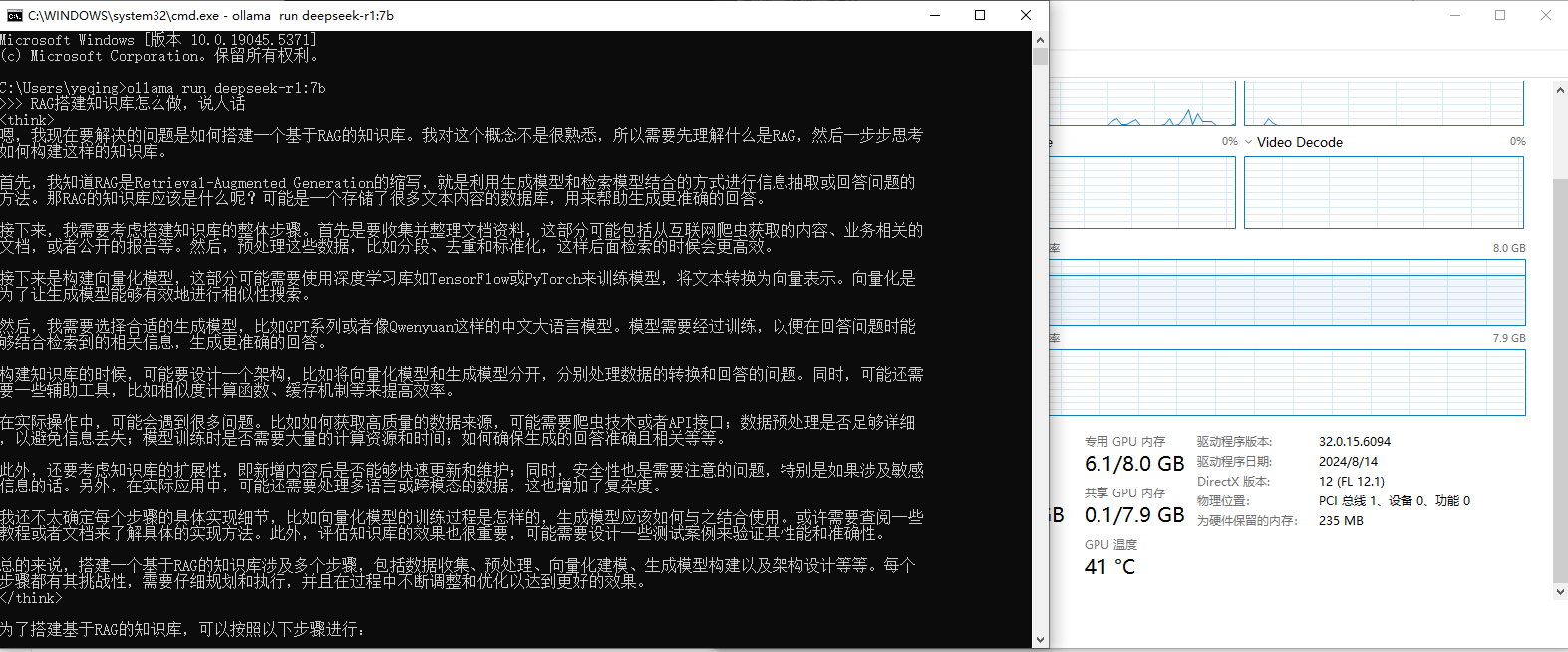
本机单靠GPU估计最多也就跑到8b参数,内存只有16G,就不去尝试更大的模型了;
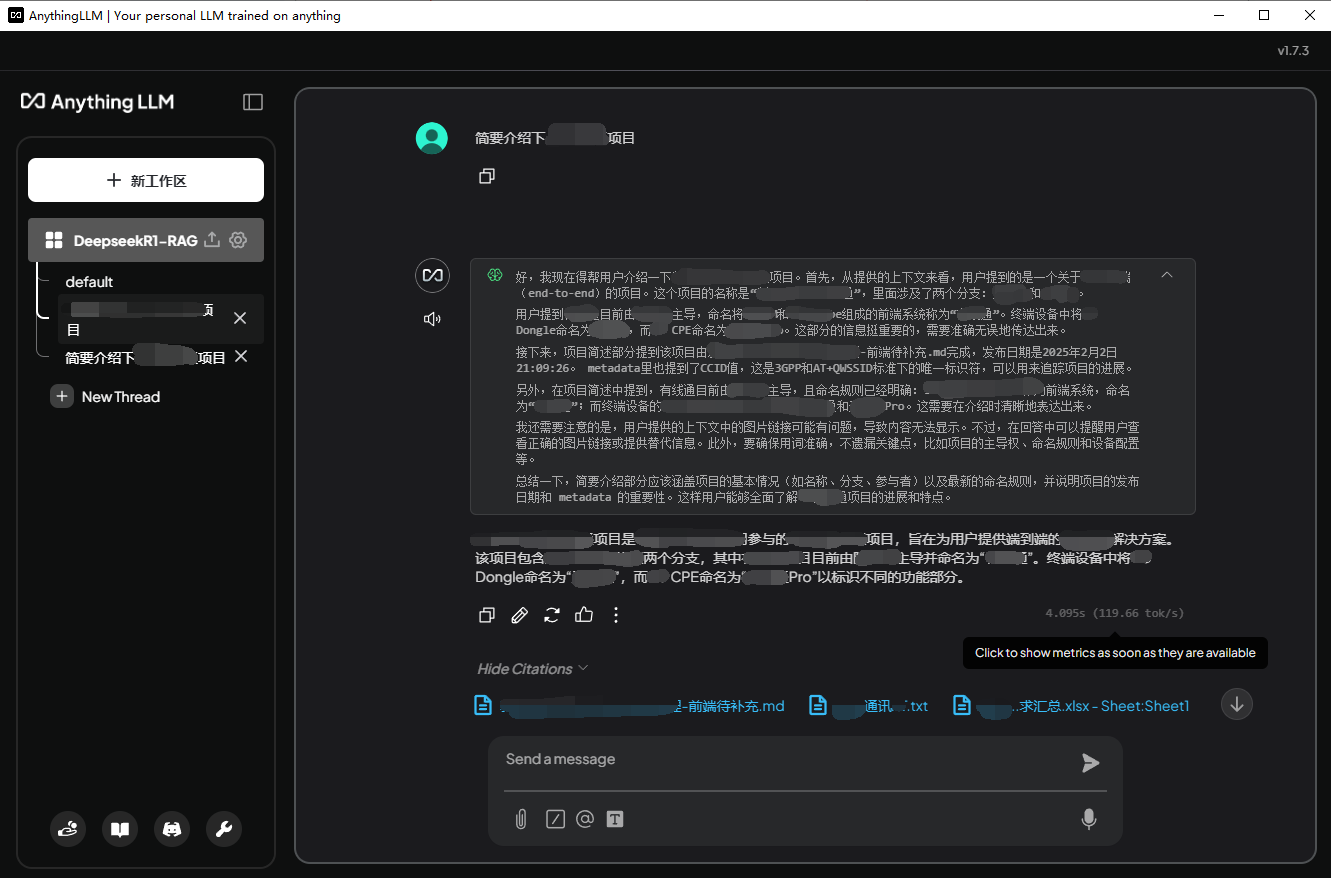
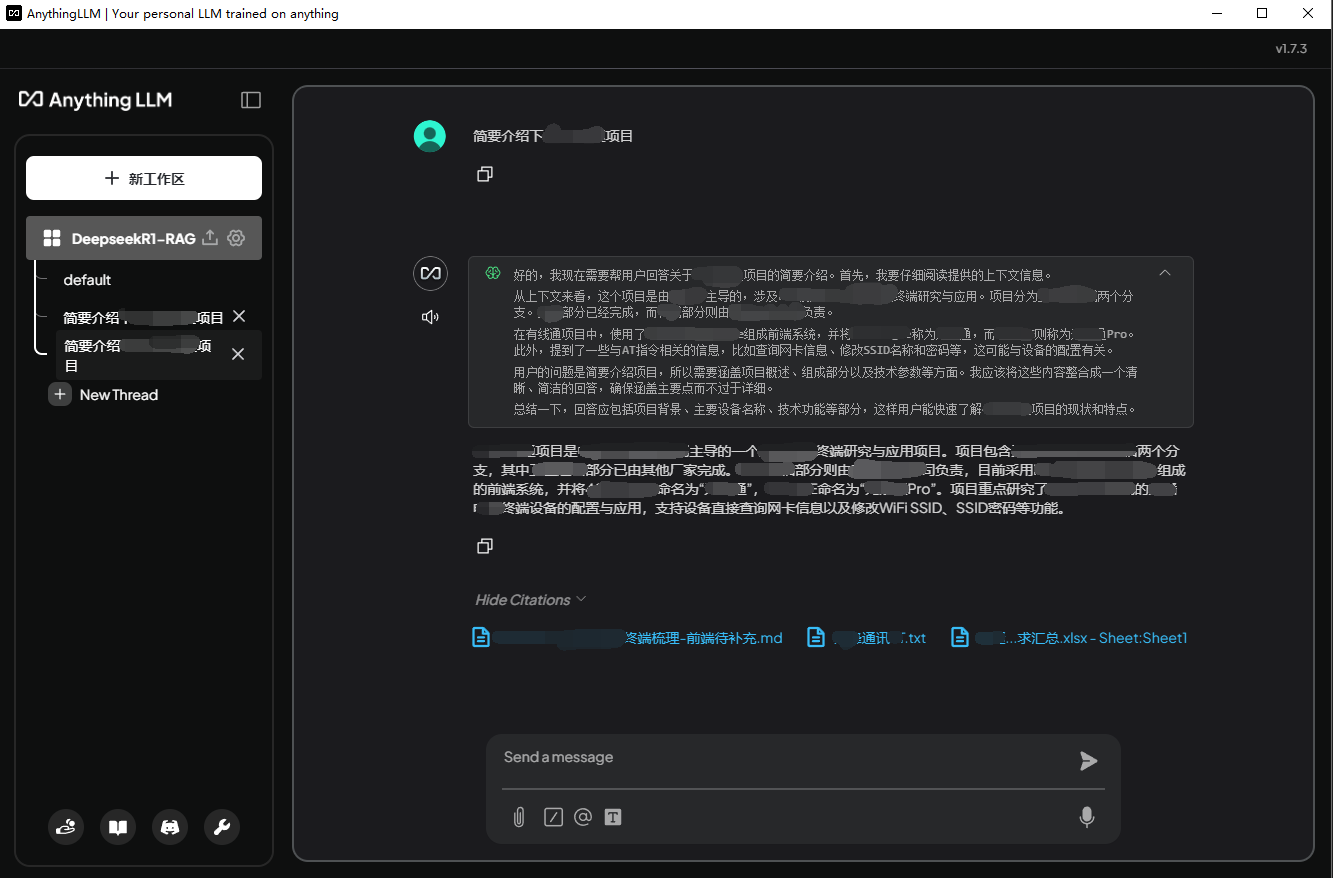
从结果看7b的回答明显比1.5b的质量有提升,满血的DeepseekR1模型是671b参数,也就是官网勾选深度思考时的回答
RAG工具
常见工具对比总结
表格来源:满血官网DeepseekR1对话,未必准确,参考
| 工具 | 核心能力 | 适合用户 | 部署复杂度 | 扩展性 |
|---|---|---|---|---|
| AnythingLLM | 企业级 RAG 框架(含 UI) | 需要私有化部署的企业团队 | 中 | 高(模块化设计) |
| Dify | 低代码 AI 应用开发 | 非技术团队/快速原型开发 | 低 | 中(依赖平台) |
| RAGflow | 复杂文档解析与高精度 RAG | 技术团队/处理结构化文档场景 | 高 | 中 |
| Chatbox | 多模型对话客户端 | 个人开发者/模型测试 | 低 | 低 |
| LangChain | 灵活编程框架 | 开发者/定制复杂 AI 逻辑 | 高 | 极高 |
看了网上一些搭建知识库的视频教程,计划如下:
AnythingLLM部署简单,功能也主要是RAG相关,用于前期搭建知识库试手
Dify的功能强大灵活度高、RAG界面更美观友好、agent应用多,Github星标多且一直在持续增长,后续研究
anythingLLM
AnythingLLM 是一个开源的、企业级大语言模型(LLM)应用框架,专为构建私有化、定制化的知识驱动型AI应用而设计。其核心目标是通过灵活的架构支持多种LLM后端(如GPT、Llama、Claude等),并结合检索增强生成(RAG)技术,实现基于私有知识库的精准问答与内容生成。
安装
登录官网下载版本安装
配置
安装完毕后选择Get started启动,初次会有一些预设的配置,先不选后续也可以修改。
比如可以在LLM Perference选择ollama,会自动读取已经安装的模型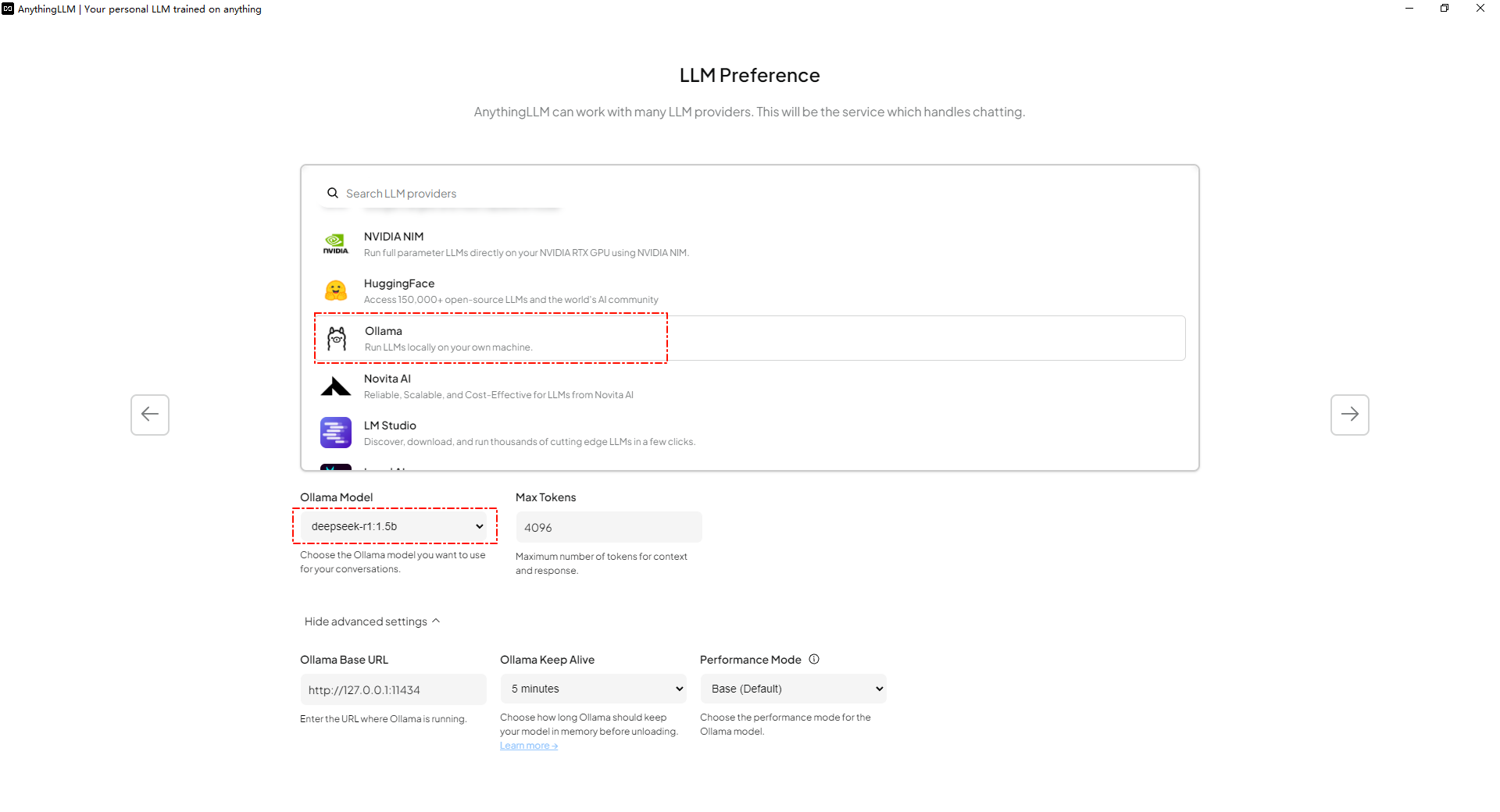
按步骤设置出工作区
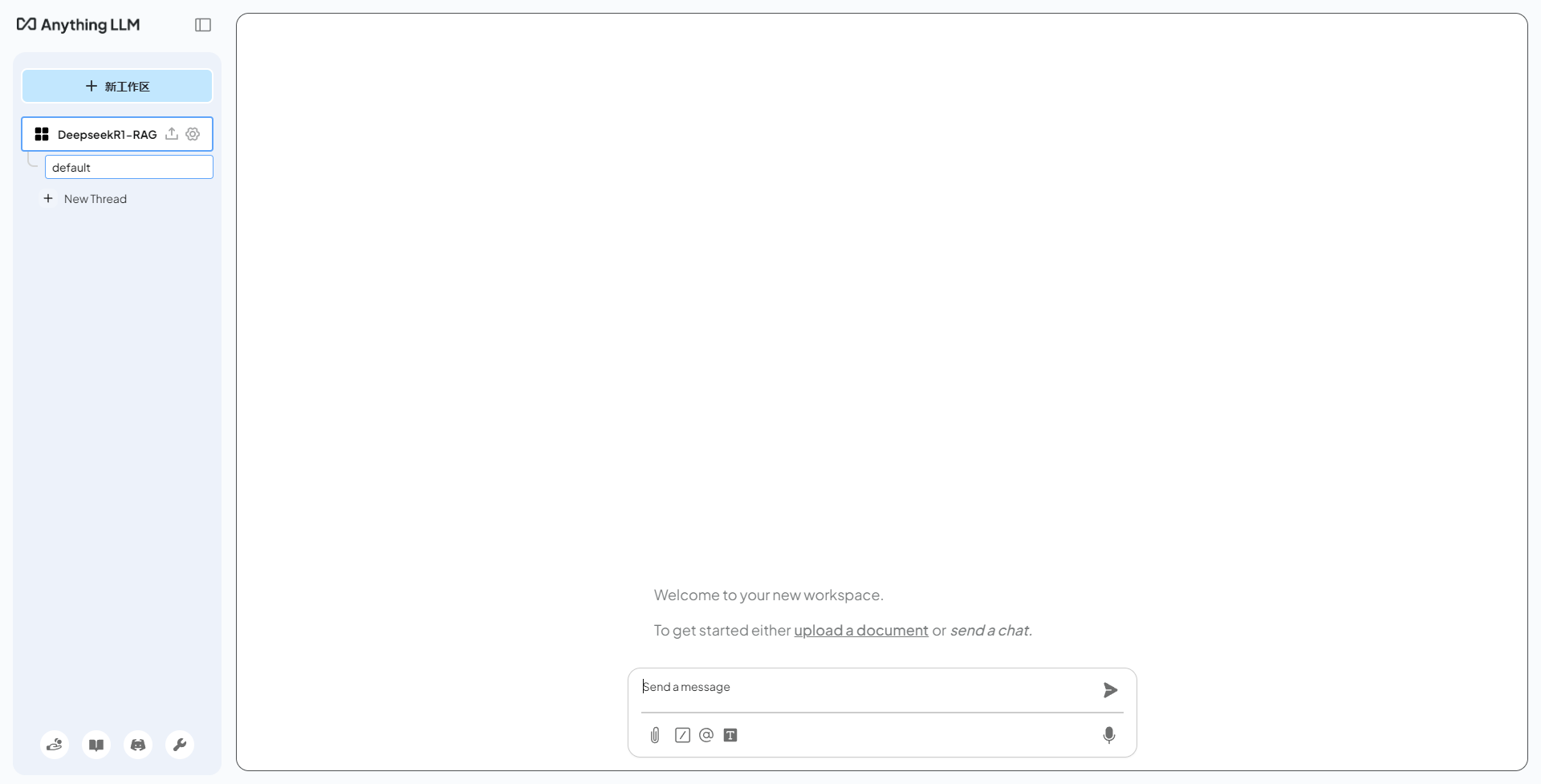
点击左下方扳手按钮进入设置页,调整模型的配置
-
LLM首选项选择之前下载的deepseek-r1:1.5b(前面设置过不用动)
-
Embedder首选项选择之前下载的nomic-embed-text:latest
-
其他的比如向量数据库配置,先不修改使用默认的
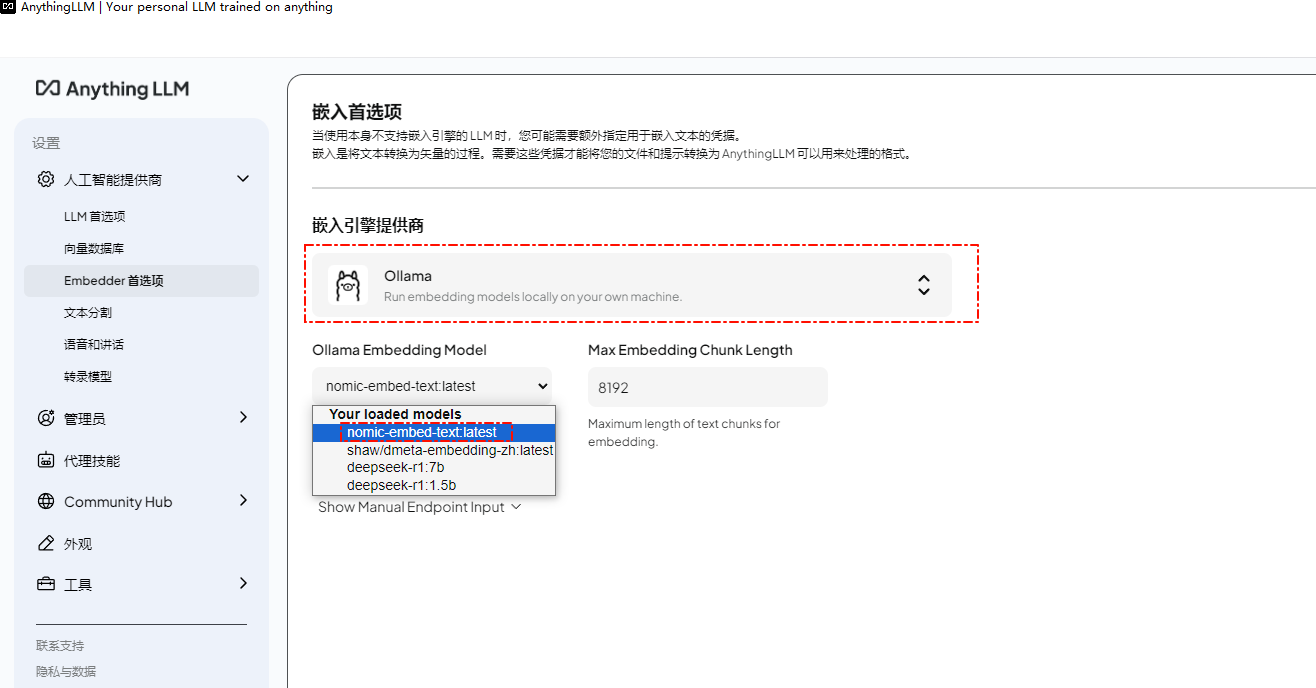
测试
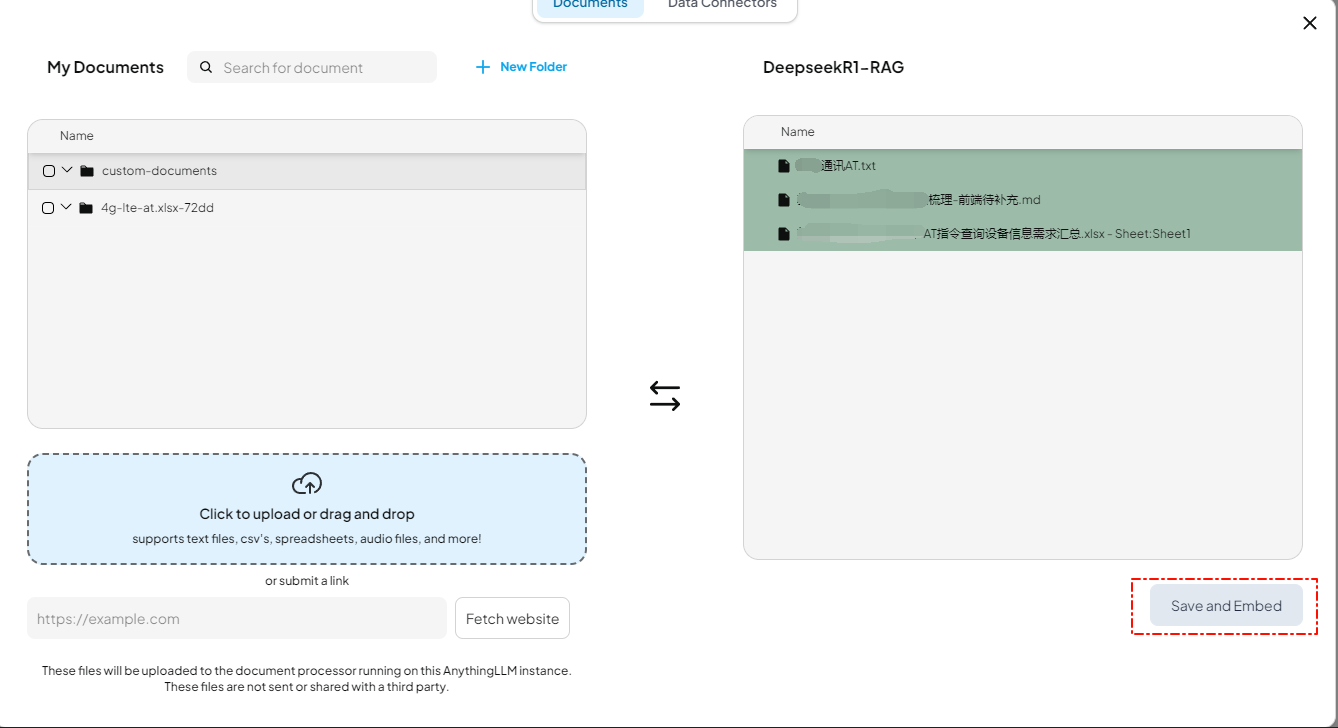
上传本地文档
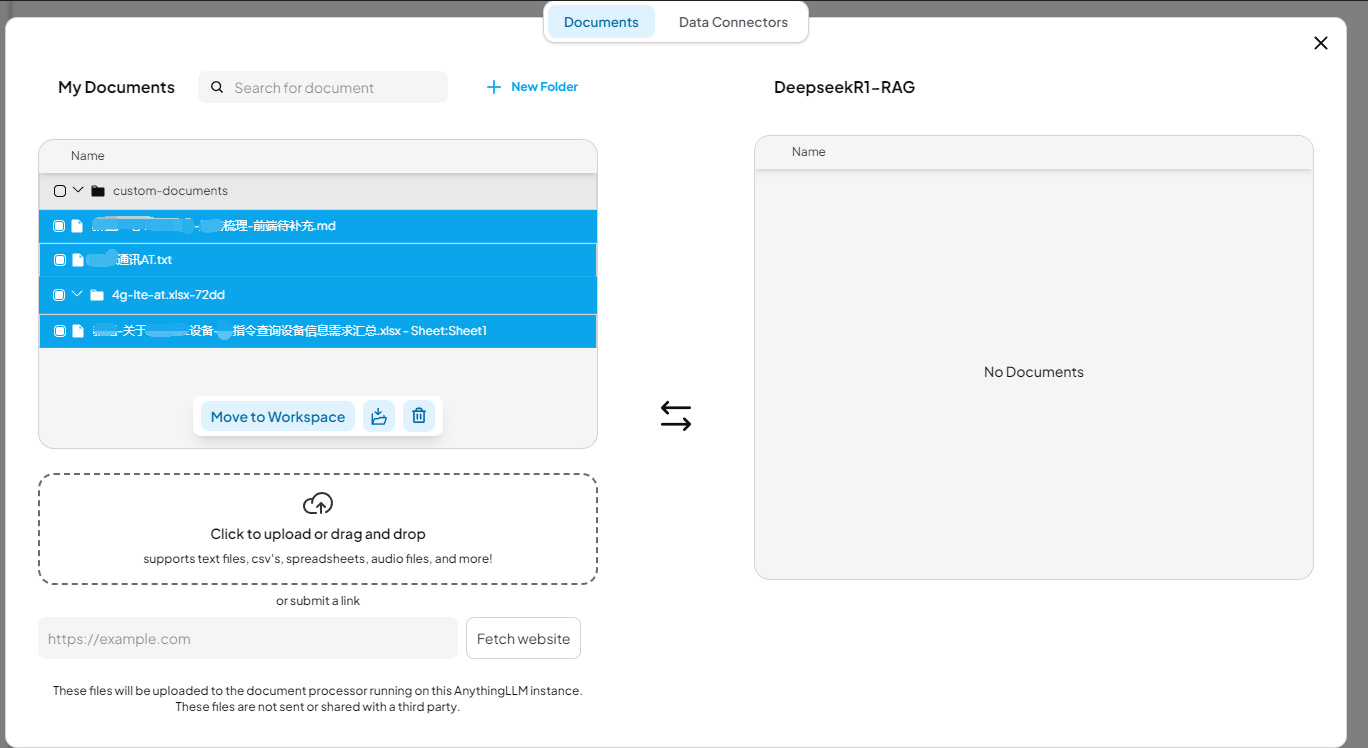
点击move to workspace,然后点击save an embed将这些文档进行向量化
对话测试
1.5b模型的回答
7b模型的回答
总结
本地搭建私有RAG知识库,数据安全、个性化定制、知识共享方面有明显优势。
-
个人私有RAG知识库适用于知识结构化积累和高效检索,适用于学习某一方向的知识记录、工作经验和技能累积等等。
-
如果要实现最优的效果,要用到参数很高的大模型版本,对硬件要求很高,个人知识库不需要,企业搭建或定制客户商务项目则需要深度评估投入产出比。
思考了一些企业的应用场景
公司内部
-
员工日常:将公司制度、办事流程、业务介绍等建立RAG知识库,员工可根据自身需求进行自助了解或查询
-
高效知识共享:将全国各个现场问题处理记录、需求&开发技术文档、产品技术文档、运营技术文档、BUG系统记录、任务系统记录等等整合进RAG知识库,员工在遇到问题时更高效的查询相关的信息,想了解某个产品或评估某个需求时能更方便的找到全国的相关信息
-
商务合作:将公司成功案例、行业最新资讯等建立RAG知识库,快捷查找到个性化的营销内容
公司客户
- 定制化自助服务:
- 将日常前线工作人员问题整理成文档进行 RAG 知识库搭建,工作人员可自助问答获取操作指南与故障解决办法,获取个性化的引导服务。
- 将可公开给目标局方的运维技术文档、故障排查处理记录产品等文档建立RAG知识库,供技术部门或产品部门高效获取目标资源。
- 其他定制化:根据客户的需求,搭建定制化RAG知识库,或可结合产品、运营内容等进行创新尝试,制造新的AI产品卖点。